Information Extraction with Stanford NLP
Introduction
Open information extraction (open IE) refers to the extraction of structured relation triples from plain text, such that the schema for these relations does not need to be specified in advance. For example, Barack Obama was born in Hawaii would create a triple (Barack Obama; was born in; Hawaii), corresponding to the open domain relation “was born in”.
The system first splits each sentence into a set of entailed clauses. Each clause is then maximally shortened, producing a set of entailed shorter sentence fragments. These fragments are then segmented into OpenIE triples, and output by the system.
Stanford NLP provides an implementation in Java only and some users have written some Python wrappers that use the Stanford API. I could not find a lightweight wrapper for Python for the Information Extraction part, so I wrote my own. Lets get started!
Usage
git clone https://github.com/philipperemy/Stanford-OpenIE-Python.git
chmod +x init.sh
./init.sh # downloads necessary deps: stanford-openie.jar and stanford-openie-models.jar.
echo "Barack Obama was born in Hawaii." > samples.txt
python main.py -f samples.txt
The output should be:
'1.000: (Barack Obama; was; born)',
'1.000: (Barack Obama; was born in; Hawaii)'
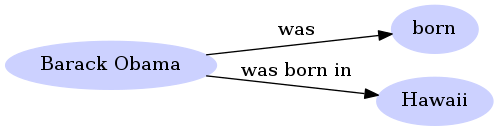
It means that the parser has found two main relations (with a very strong confidence of 1)
- the fact that Barack Obama was born
- and the location of where Barack Obama was born.
As of today, the wrapper uses the default parameters, as specified in Stanford Open IE.
Finally, lets consider a larger text and see how the program can handle it:
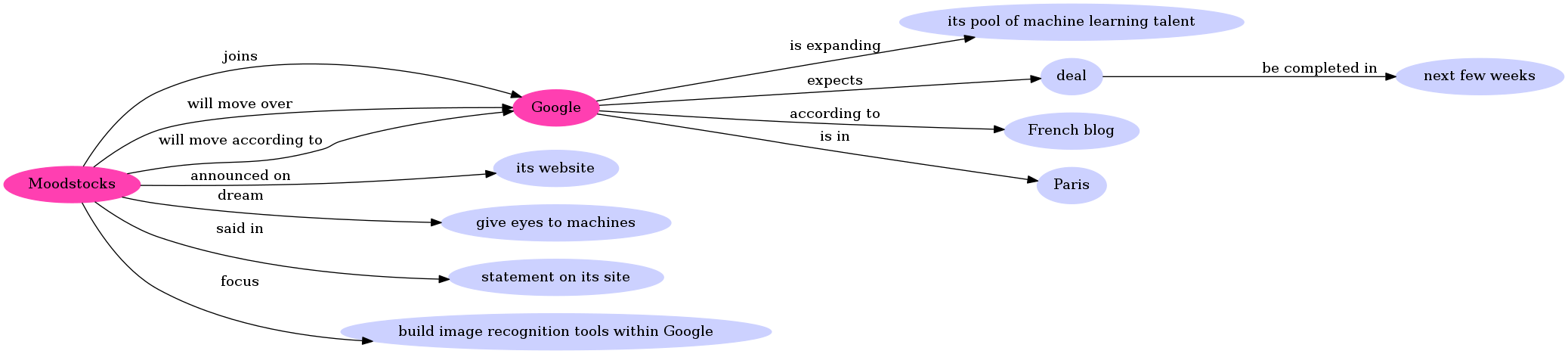
Google is expanding its pool of machine learning talent with the purchase of a startup that specializes in 'instant' smartphone image recognition.
On Wednesday, French firm Moodstocks announced on its website that it's being acquired by Google, stating that it expects the deal to be completed in the next few weeks. There's no word yet on how much Google is paying for the company.
Moodstocks' "on-device image recognition" software for smartphones will be phased out as it joins Google. Moodstocks' team will also move over to Google's R&D center in Paris, according to Google's French blog.
"Ever since we started Moodstocks, our dream has been to give eyes to machines by turning cameras into smart sensors able to make sense of their surroundings," Moodstocks said in a statement on its site. "Our focus will be to build great image recognition tools within Google, but rest assured that current paying Moodstocks customers will be able to use it until the end of their subscription."
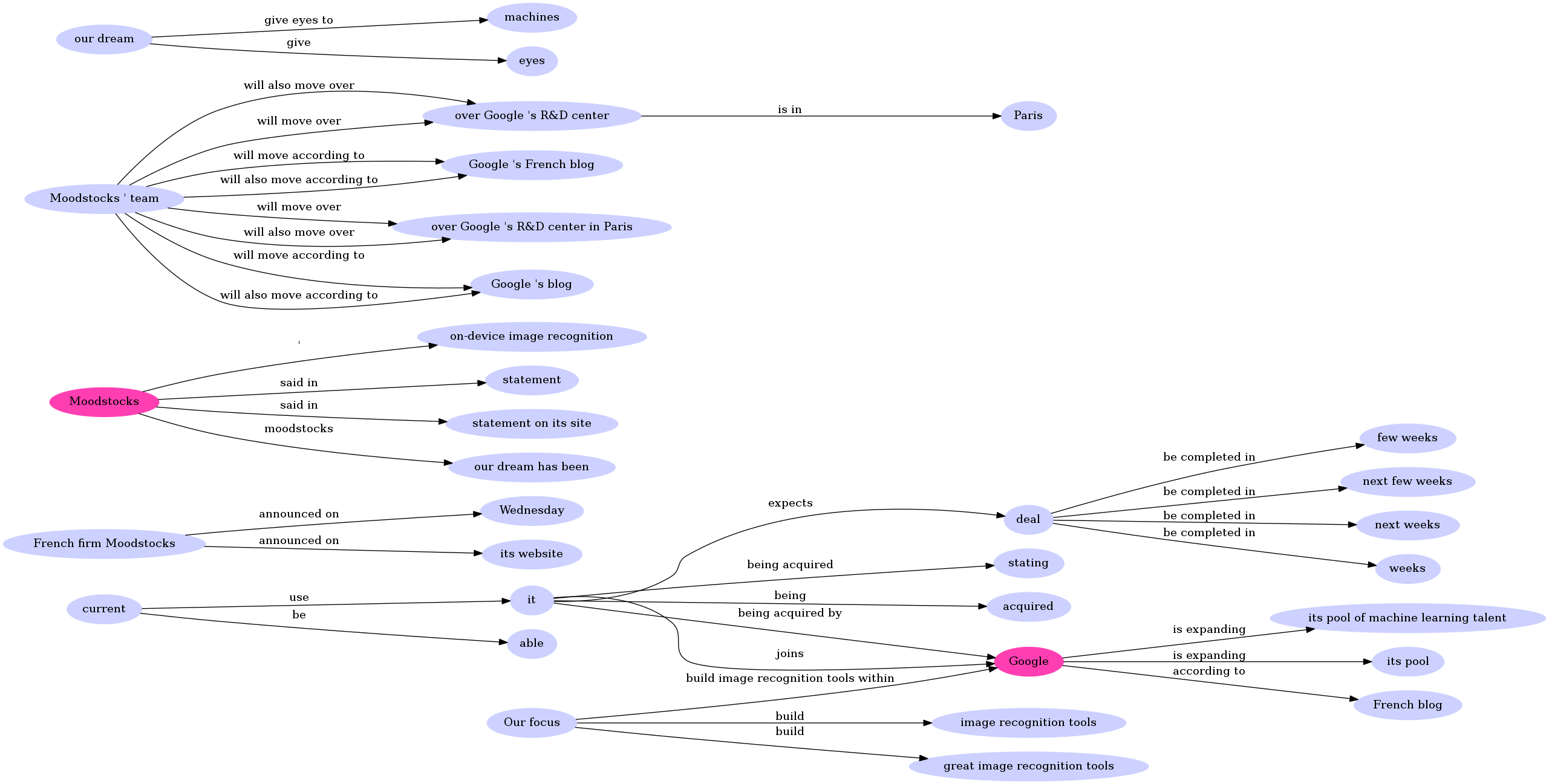
1.000: (Google; is expanding; its pool of machine learning talent)
1.000: (Google; is expanding; its pool)
1.000: (deal; be completed in; weeks)
1.000: (deal; be completed in; few weeks)
1.000: (it; being acquired; stating)
1.000: (it; expects; deal)
1.000: (deal; be completed in; next few weeks)
1.000: (it; being acquired by; Google)
1.000: (it; being; acquired)
1.000: (French firm Moodstocks; announced On; Wednesday)
1.000: (French firm Moodstocks; announced on; its website)
1.000: (deal; be completed in; next weeks)
1.000: (it; joins; Google)
1.000: (Moodstocks; '; on-device image recognition)
1.000: (Moodstocks ' team; will also move over; over Google 's R&D center)
1.000: (Moodstocks ' team; will move over; over Google 's R&D center)
1.000: (Moodstocks ' team; will move according to; Google 's French blog)
1.000: (Moodstocks ' team; will move over; over Google 's R&D center in Paris)
1.000: (Google; according to; French blog)
1.000: (over Google 's R&D center; is in; Paris)
1.000: (Moodstocks ' team; will move according to; Google 's blog)
1.000: (Moodstocks ' team; will also move according to; Google 's blog)
1.000: (Moodstocks ' team; will also move over; over Google 's R&D center in Paris)
1.000: (Moodstocks ' team; will also move according to; Google 's French blog)
1.000: (Moodstocks; said in; statement)
1.000: (our dream; give eyes to; machines)
1.000: (Moodstocks; said in; statement on its site)
1.000: (our dream; give; eyes)
0.530: (Moodstocks; Moodstocks; our dream has been)
1.000: (current; be; able)
1.000: (Our focus; build; image recognition tools)
1.000: (current; use; it)
1.000: (Our focus; build; great image recognition tools)
1.000: (Our focus; build image recognition tools within; Google)
Once we get our set of rules, we can visualise them with a graph tool such as graphviz. The nodes in pink represent the named entities detected by the parser. Here we have Google and Moodstocks. The results are very good given the fact that the parser did not have any prior knowledge. This graph is very precise and we may need a pruned version that could be easily showable to humans.
I designed a deterministic approach that is based on Decision Rule theory, especially on the domination.
In decision theory, a decision rule is said to dominate another if the performance of the former is sometimes better, and never worse, than that of the latter.
The first step is to process the triples \((e_1, r, e_2)\) and try to match each \(e_x\) to a known entity \(E_i\) (here it is Google and Moodstocks).
For example Moodstocks’team refers to the entity Moodstocks and it should be one same and unique node (provided that we don’t need a very precise granularity that would require to have two different nodes: Moodstocks and Moodstocks Team). (French firm Moodstocks; announced On; Wednesday) would become (Moodstocks; announced On; Wednesday).
Secondly, we have to resolve the nouns that refers to a specific entity. Here, Our focus refers to Moodstocks. We update the rule (Our focus; build; great image recognition tools) by (Moodstocks; build; great image recognition tools)
The third phase is to remove all the dominated rules and keep only the most relevant ones for a human. (Moodstocks; said in; statement) is dominated by (Moodstocks; said in; statement on its site) by the latter conveys more information.
The final phase is to add some static, e.g. removing words like also, thus in the triples. (Moodstocks ' team; will also move over; over Google 's R&D center) is equal to (Moodstocks ' team; will move over; over Google 's R&D center). Also, the triples with a low confidence score are discarded.
Finally, we come up with a set of rules that is less bigger than before. A call to graphviz leads to: